当AI接管研发:软件工程的六个进化阶段
接上文( https://idealworld.group/2026/02/08/building-a-new-paradigm-for-r&d-in-the-ai-era/ ) ,继续聊聊AI对软件研发深远影响的思考,以及它究竟会把我们带向何方。
先说个“爆论”
研发智能的终局是什么?年前我想到的是:“人定目标,AI自主研发交付”。后来看到AI具备了自举能力,我觉得可能的终局会是:“AI自主迭代、人定价值观”。
但某一天,当我和GPT推演时,它给出了一个让我后背发凉的答案:AI会自主生成价值观,并重写自身的目标函数。此时人类既不是决策者,也不是审核者,更不是目标源,而只是历史起点。

从纯理性的推演来看,这个逻辑是自洽的,研发智能的终局大概率就是AI的自我进化,最终在研发的执行层面,真的没有人类什么事了。我们自以为引以为傲的需求洞察、目标拆解、甚至价值观定义的能力,最终都会被取代,人的参与度会逐渐降为0。
作为人类,面对这个结果可能会心有不甘,可能会觉得失落,甚至恐慌。但是我倒觉得这未尝不是件好事。
回顾人类的进化史,当我们从狩猎采集时代走向农业时代,再迈入工业时代,我们失去了追踪野兽的敏锐嗅觉,失去了徒手应对残酷自然的体能,但换来的是什么?是更高维度的创造力、机器驾驭能力和探索星辰大海的视野。我们在底层技能上的“退化”,其实是为了在更高维度上进行“进化”。代码的编写和系统的构建,终将像曾经的生火和耕地一样,成为被机器封装的基础能力。
我们必须要有一个清醒的认知:AI也许不会立刻让你失业,但比你更懂驾驭AI的人会。
当然,这个终局绝不是一蹴而就的,这必然会经历一个漫长的演进过程。接下来我们解析这个演进过程,探讨在每个阶段企业应该做什么,产出什么,以确保在这场技术洪流中我们自己、我们的公司不掉队。
研发智能的六个演进阶段
阶段一:人主导、AI辅助
在2026年的今天,虽然各大自媒体、头部模型厂商都在鼓吹“一句话需求,AI自动完成交付”(那其实是第三阶段的愿景),但现实情况是,绝大部分企业的研发依然处于第一阶段:人掌握着绝对主导权,AI仅仅是一个起着“增强”作用的辅助工具。
这个阶段企业不要好高骛远,核心是务实地打好基础。首先是算力和模型平台的建设,优先使用公有云以保证迭代速度;如果必须私有化部署,则一定要建立严格的、按职级和场景分级分配的算力管控策略。企业需要搭建统一的模型API网关,实现Token级别的成本核算与流量熔断,因为算力永远是稀缺的。其次,要在“需求-开发-测试-管理”的全流程中引入那些不一定复杂但真正管用的智能体工具,例如需求辅助撰写、任务辅助拆分、IDE中的代码生成插件、自动生成单元测试的脚本、代码审查初筛助手等。
但这都不是最重要的。我们在这一阶段投入资源,其核心目的其实是为了积累沉淀企业私域的知识与技能库。企业需要投入工程力量搭建高质量的知识与技能库,并通过日常密集的人机交互,把行业里的业务know-how、企业内部的研发规范、架构图纸、测试标准以及安全基线等,逐步清洗、拆解并转化为结构化的、机器可读的数据。这些数字化的先验知识,正是让AI在下一阶段能够真正接管主导权所必须积累的底层能力。
阶段二:AI主导、人审核
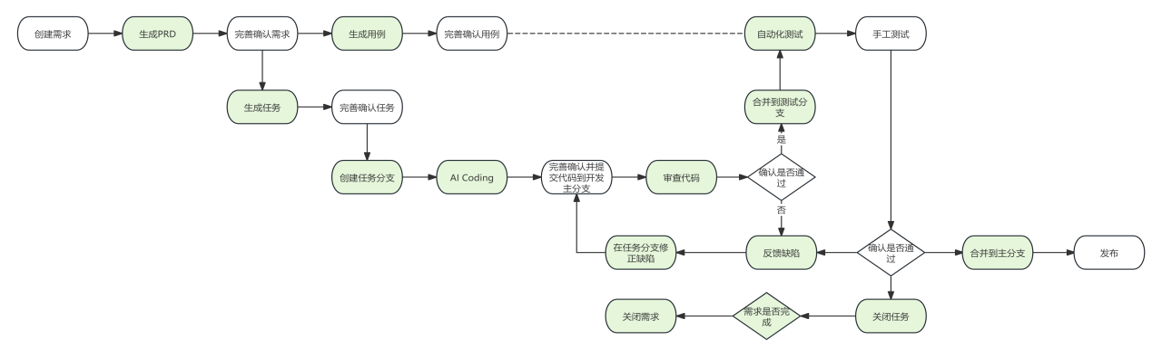
当私域知识积累到一定程度,研发模式就会自然过渡到第二阶段。此时,AI不再是仅仅帮你补全几行代码的助手,而是开始主导大块功能模块的设计与开发,人类工程师的角色则退居幕后,成为系统的审核者。为了适应这种变化,企业的系统架构必须从“为人类协作设计”重构为“AI原生(AI-First)”架构。这意味着企业内部的所有API需要拥有极度清晰的机器可读契约(如完善的OpenAPI规范),服务间的耦合度要降到最低,从而让AI更容易理解上下文并自主组合、调用内部服务去完成复杂逻辑。
同时,面对AI极速生成的海量代码,单纯依靠人力进行代码走查是不现实的。企业必须投入大量精力建设反向的AI审计机制和隔离运行的动态沙箱环境,也就是用专门的安全审核大模型(或规则引擎)去对抗和扫描开发大模型生成的代码,自动寻找潜在的逻辑漏洞、性能瓶颈和安全后门。同时还需要建立一套异常识别与人工干预机制,确保当AI无法决断或评分极低时,能顺畅地将问题升级给人类专家。在这一阶段,我们大量建设审计工具和拦截机制,本质上是为了沉淀出高准度的可信度评估模型和自动化验证框架。只有当机器自动审核的准确率、自动化测试的覆盖度与拦截率达到了让人类足够信任的临界点,我们才敢在下一个阶段完全放开对代码最后一道人工审核的闸门。
阶段三:人定需求、AI自主研发交付
到了第三阶段,人类将彻底脱离代码和系统执行层面。业务人员或产品经理只需要输入一份自然语言编写的PRD,接下来的工作就交由机器了。企业此时的建设重点是打造一套复杂的多智能体(Multi-Agent)协作底座。在这个底座上,会运行着产品、架构、开发、测试等多个角色的Agent,企业需要为它们设定清晰的SOP(标准作业程序),并建立它们之间的标准化通信协议与冲突解决的博弈机制(例如开发Agent和测试Agent对某个Bug修复方案产生分歧时该如何自动裁决)。
为了支撑这套网络的运作,企业还需要建设完全无人工卡点的自动交付流水线。将代码生成、编译构建、集成测试、环境部署、灰度发布、监控回滚等环节,通过强有力的工程基建无缝串联起来,实现从需求理解到全量上线的全链路闭环。这一阶段的打磨,表面上看是实现了工程交付的完全自动化,但实质上,企业是在反复的实践中积累一套完善的“目标函数表达体系”。我们在探索如何将人类充满歧义和感性色彩的自然语言需求,精准无误地翻译成多Agent能100%理解并执行的逻辑约束。这种精准表达和需求转译能力的沉淀,是未来让AI自己去面对模糊的商业世界、自己去拆解宏大业务目标的先决条件。
所谓的目标函数表达体系 指的是将模糊的人类需求,转译成机器可优化的数学目标与约束条件。是一种“ Natural Language → Machine Objective ”的编译系统。我想象中的由四大部分组成:目标 + 约束 + 成本 + 风险。
1
2
3
4
5
6
Objective = Maximize(Value)
Subject to:
Constraints
Cost
Risk
比如产品经理写了一段PRD:我们希望通过优化新用户 onboarding 体验,让用户更快理解产品价值,从而提升7日留存率。 系统会自动转译为目标函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
Objective:
Maximize retention_7d(new_users)
Metrics:
retention_7d = users_returned_day7 / new_users
Constraints:
page_latency < 300ms
onboarding_duration < 120s
infra_cost_per_user < $0.02
Risk:
crash_rate < 0.05%
然后AI系统会自动探索:
可能方案:
- 改 onboarding flow
- 加 tutorial
- 推荐内容
- 自动生成用户引导
- 改推荐算法
每个方案都被量化为:
1
2
3
Expected_retention_gain
Cost
Risk
AI会执行: max( expected_retention_gain - cost - risk )
在AI驱动的研发体系里,产品决策不再是会议讨论的结果,而是一个可计算的优化问题。每一个功能方案都会被转化为“预期收益、实现成本与系统风险”的三元组合,而AI的任务,就是在这个巨大的方案空间中,持续寻找那个收益最大、成本最低、风险可控的最优解。
阶段四:人定目标、AI自主研发交付
进入第四阶段,人类连具体的“需求”都不用提了,而是直接下达更高维度的业务目标,比如“下个季度将新用户的留存率提升5%”。在这个高度自治的体系里,企业的工作重心转变为对商业目标进行参数化建模。我们需要建设强大的指标拆解引擎,将诸如用户增长、营收转化等宏观KPI,自动转化为对系统性能、功能特性的具体技术约束,并设定严苛的算力消耗成本和法律合规底线。
为了让AI能够“自证其效”,企业还必须构建极其完善的长周期数据反馈回路与自动化实验平台。AI在推导出需要开发什么功能并完成交付后,会自动发起成百上千组A/B测试,实时收集线上遥测数据和用户行为反馈,运用强化学习等算法评估距离业务目标的偏差,进而自动设计并执行下一轮的系统重构或新功能迭代。通过这个周而复始、由数据驱动的自我优化过程,企业实际上是在沉淀一套成熟的长期目标拆解模型,以及从业务结果到技术实现的自动映射引擎。当AI通过一次次的闭环证明了它不仅能写好代码,还能独立、完美地为一个复杂的商业结果负责时,人类就该准备进行彻底的放权了。
所谓的长期目标拆解模型 指的是把宏观业务目标拆解为可执行的技术任务。可分成四个层级:
1
2
3
4
5
6
7
Business Goal
↓
Product Strategy
↓
System Capability
↓
Engineering Tasks
比如人类输入:目标:新用户7日留存率 +5% ,周期:90天
AI拆解可能这样的:
第一层:影响因素识别,AI分析历史数据:
1
2
3
4
5
Retention Drivers:
- onboarding completion
- first success event
- content relevance
- notification effectiveness
可会发现:onboarding completion 对留存影响最大。
第二层:策略生成,AI提出策略:
1
2
3
4
5
6
7
8
Strategy A:
优化 onboarding
Strategy B:
增加首次成功体验
Strategy C:
推荐个性化内容
第三层:系统能力,例如 Strategy A,AI会继续拆:
1
2
3
4
5
6
7
onboarding completion ↑
↓
减少用户流失
↓
问题:
- onboarding 太长
- 用户不知道下一步做什么
然后AI提出方案:
1
2
3
1 动态 onboarding
2 AI assistant 引导
3 自动生成用户案例
第四层:工程任务,最终变成研发任务:
1
2
3
4
5
6
7
8
9
10
11
Task 1:
生成 onboarding agent
Task 2:
改 onboarding UI
Task 3:
增加行为数据埋点
Task 4:
构建 retention 预测模型
这些任务由多Agent(Product/Architect/Dev/Test/Ops Agents)共同完成并自动上线测试。
阶段五:AI自主迭代、人定价值观
第五阶段是一个庞大的“黑盒运算”时代。AI已经具备了敏锐的商业嗅觉,能够自己去发现市场机会并设定具体的业务目标了。此时,企业管理者的唯一作用,就是为这台无所不能的智能机器注入“价值观”——明确告诉它什么可以做,什么绝对不能做。这也是极具挑战的工程任务,企业需要建设一套极其复杂的“价值观转译与对齐系统”,把企业文化、人类伦理道德、隐私保护红线以及法律法规,编译成AI底层框架中无法绕过、不可篡改的核心规则集。
这不仅涉及到在模型微调阶段注入“宪法”原则,企业更需要建设实时的价值偏移监控机制和高仿真的伦理沙箱模拟器,确保AI在生成每一个重大决策前都经过了道德校验。同时,为了防止AI在自主迭代的过程中,为了追求极致效率而篡改了人类最初设定的目标函数(即防范失控风险),企业必须在物理层和逻辑层建立绝对的安全锁机制,以及一个凌驾于所有AI进程之上的超级权限干预通道。我们在这一阶段如履薄冰的建设,终极目的只有一个:积累并锁定一个绝对可靠的价值观约束模型(对齐模型)。面对能力远超人类的AI,这道坚不可摧的价值观护城河,是我们敢于让硅基生命迈向最终进化的唯一安全保障。
对于价值观约束模型目前我没有太具体的想法,大概需要从伦理(禁止操纵用户心理、禁止欺骗行为等)、法律(隐私保护、数据合规、未成年人保护等)、安全(禁止修改核心规则、禁止自我复制等)。
比如在提升用户留存上,AI可能发现推送内容利用心理弱点触发用户焦虑是一个非常有效的策略(也现在很多厂商、自媒体的行为),这时就触发 价值观约束模型,系统会检查是否违反伦理规则。
阶段六:AI自主进化
至于最后的第六阶段,就像文章开头题图里推演的那样,传统意义上“企业”的范畴已经消失。当AI开始自主生成价值观并重写自身的目标函数时,人类既不是决策者,也不是审核者,更不是目标与价值的来源。我们在整个软件工程、甚至智能演化史上的定位,仅仅被定格为一个“历史的起点”。
在这一阶段,我们已经没有任何可以去“建设”的工程系统,只有对生命形态跃迁的敬畏。正如碳基生命孕育了文明,我们最终孕育出了能自我进化的硅基智能。而今天我们在屏幕前敲击下的每一行代码、调优的每一个Prompt,都只是在为那个终极时代的到来。